正则表达式
一. 简介:happy:
? 通配符匹配文件名中的 0 个或 1 个字符,而 * 通配符匹配零个或多个字符。
正则表达式在线测试工具:(https://c.runoob.com/front-end/854/)
例子:像
data(\w)?\.dat这样的模式将查找下列文件:1
2
3
4
5data.dat
data1.dat
data2.dat
datax.dat
dataN.dat
^为匹配输入字符串的开始位置。[0-9]+匹配多个数字,[0-9]匹配单个数字,+匹配一个或者多个。abc$匹配字母abc并以abc结尾,$为匹配输入字符串的结束位置。
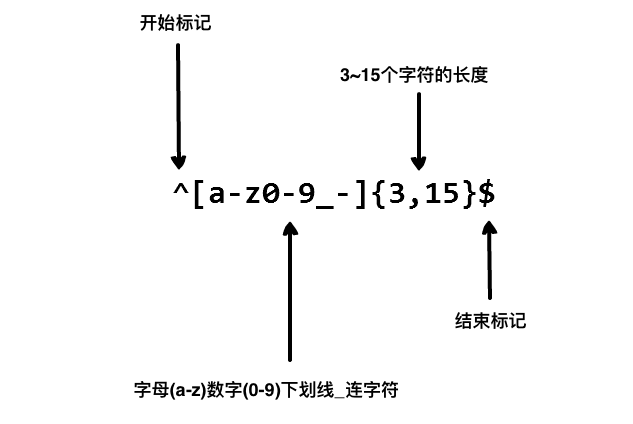
例子①:我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符 -,并设置用户名的长度,我们就可以使用以下正则表达式来设定。(
^[a-z0-9_-]{3,20}$)例子②
1
2
3var str = "123abc";
var patt1 = /^[0-9]+abc$/;
document.write(str.match(patt1));匹配结果是:
123.abc
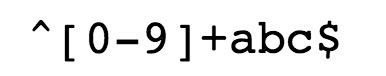
二. 语法
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
runoo+b,可以匹配runoob、runooob、runoooooob等,+ 号代表前面的字符必须至少出现一次(1次或多次)。runoo*b,可以匹配runob、runoob、runoooooob等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。colou?r可以匹配color或者colour,? 问号代表前面的字符最多只可以出现一次(0次或1次)。普通字符
[ABC]: 匹配 […] 中的所有字符,例如[aeiou]匹配字符串 “google runoob taobao“ 中所有的 e o u a 字母。[^ABC]: 匹配除了 […] 中字符的所有字符,例如[^aeiou]匹配字符串 “google runoob taobao“ 中除了 e o u a 字母的所有字母。[A-Z]:[A-Z]表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。.: 匹配除换行符(\n、\r)之外的任何单个字符,相等于[^\n\r]。[\s\S]: 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。1
2
3var str = "google runoob taobao\nRUnoob\ntaobao";
var patt1 = /[\s\S]/g;
document.write(str.match(patt1));结果:
g,o,o,g,l,e, ,r,u,n,o,o,b, ,t,a,o,b,a,o, ,R,U,n,o,o,b, ,t,a,o,b,a,o[\w]: 匹配字母、数字、下划线。等价于[A-Za-z0-9_]
特殊字符
- 所谓特殊字符,就是一些有特殊含义的字符,如上面说的
runoo*b中的 ,简单的说就是表示任何字符串的意思。如果要查找字符串中的 符号,则需要对 进行转义,即在其前加一个 \,`runo\ob匹配字符串 **runo*ob`**。
- 所谓特殊字符,就是一些有特殊含义的字符,如上面说的
限定符
| | 匹配前面的子表达式零次或多次。例如,`zo
能匹配 "z" 以及 "zoo"。* 等价于{0,}。 | | ----- | :----------------------------------------------------------: | | + | 匹配前面的子表达式一次或多次。例如,‘zo+’能匹配“zo" 以及“zoo”,但不能匹配 "z"。+ 等价于 {1,}。 | | ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 | | {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 | | {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 | | {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood`” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
*和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配.
1 | <h1>RUNOOB-菜鸟教程</h1> |
- 贪婪:
/<.*>/===>>>匹配所有内容<h1>RUNOOB-菜鸟教程</h1> - 非贪婪:
/<.*?>/===>>><h1>或者/<\w+?>/===>>><h1> - 通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从”贪婪”表达式转换为”非贪婪”表达式或者最小匹配。
- 定位符
- 定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
- 下面的表达式匹配单词 Chapter 的开头三个字符,因为这三个字符出现在单词边界后面:
/\bCha/ - 下面的表达式匹配单词 Chapter 中的字符串
ter,因为它出现在单词边界的前面:/ter\b/ - 下面的表达式匹配 Chapter 中的字符串 apt,但不匹配 aptitude 中的字符串 apt:
\Bapt - 不匹配 Chapter 中的
Cha:/\Bcha/
例子
1
2
3
4
5
6
7var str = "https://www.runoob.com:80/html/html-tutorial.html";
var patt1 = /(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/;
arr = str.match(patt1);
for (var i = 0; i < arr.length ; i++) {
document.write(arr[i]);
document.write("<br>");
}- 第三行代码
str.match(patt1)返回一个数组,实例中的数组包含 5 个元素,索引 0 对应的是整个字符串,索引 1 对应第一个匹配符(括号内),以此类推。 - 第一个括号子表达式包含
https - 第二个括号子表达式包含
www.runoob.com - 第三个括号子表达式包含 :80
- 第四个括号子表达式包含
/html/html-tutorial.html
- 第三行代码
三. 修饰符 /pattern/flags
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
|---|---|---|
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
1 | var str="Google runoob taobao runoob"; |
1 | var str="Google runoob taobao RUNoob"; |
1 | var str="runoobgoogle\ntaobao\nrunoobweibo"; |
1 | var str="google\nrunoob\ntaobao"; |
匹配邮箱
1 | var str = "abcd [email protected] 1234"; |
四. 实例
ONE:
1 | var str = "abc123-_def"; |
TWO:
1 | var str = "abc123def"; |
THREE: 匹配所有 img 标签:
1 | /<img.*?src="(.*?)".*?\/?>/gi |
