Redis的基本操作和运用
一. 什么是NOSQL?
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,它泛指非关系型的数据库。随着互联网2003年之后web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的交友类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
关系型数据库:有行有列,能组成二维表的数据库.
二. Redis
1. 什么是Redis
Redis 是一个高性能的 开源的、C语言写的Nosql(非关系型数据库),数据保存可以存储在内存中或者磁盘中。Redis 是以key-value形式存储,和传统的关系型数据库不一样。不一定遵循传统数据库的一些基本要求,比如说,不遵循sql标准,事务,表结构等等,redis严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
2. Redis的特点
- 数据保存在内存,存取速度快,并发能力强。
- 它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、 zset(sorted set —有序集合)和hash(哈希类型)。
- redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库(如MySQL)起到很好的补充作用。
- 提供了Java,C/C++,C#,PHP,JavaScript等客户端,使用很方便。
- Redis支持集群(主从同步)。数据可以主服务器向任意数量从的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。
- 支持订阅/发布(subscribe/publish)
- 支持事务
3. Redis和Mysql比较
| mysql | redis | |
|---|---|---|
| 类型 | 关系型 | 非关系型 |
| 存储位置 | 磁盘 | 磁盘和内存 |
| 存储过期 | 不支持 | 支持 |
| 读写性能 | 低 | 非常高 |
4. Redis的使用场景
缓存(以空间换时间)
经常查询数据,放到读速度很快的空间(内存),以便下次访问减少时间。减轻数据库压力,减少访问时间.而redis就是存放在内存中的。就如同:Mybatis 二级缓存 , ehcache框架 缓存。
计数器
网站通常需要统计注册用户数,网站总浏览次数等等 ,新浪微博转发数、点赞数。
实时防攻击系统。
防止暴力破解,如使用工具不间断尝试各种密码进行登录。解决方案使用Redis记录某ip一秒访问到达10次以后自动锁定IP,30分钟后解锁。
设定有效期的应用
设定一个数据,到一定的时间失效。验证码,登录过期, 自动解锁,购物券,红包。
自动去重应用
Uniq操作,获取某段时间所有数据排重值 这个使用 Redis 的 set 数据结构最合适了,只需要不断地将数据往 set 中扔就行了,set 意为 集合,所以会自动排重。
队列
构建队列系统 使用 list 可以构建队列系统,使用 sorted set 甚至可以构建有优先级的队列系统。
秒杀:可以把名额放到内存队列(redis),内存就能处理高并发访问。
分布式锁
三. Redis的安装
1. 下载地址:windows版,解压即安装
2. Redis目录介绍
1 | redis.windows.conf #【重要】reids配置文件 |
3. Redis启动和测试
进入到Redis安装目录 ,虽然双击也可以启动,但是建议使用CMD执行
1
redis-server.exe redis.windows.conf
启动redis-client
连接本机Redis直接双击 redis-cli.exe 或者执行命令
1
redis-cli.exe
如果连接其他服务的Redis需要跟上 -h参数
1
redis-cli.exe -h ip -p 端口 # 如 redis-client.exe -h 192.168.0.11 -p 6379
测试redis
1
2
3set name lqs # 设置数据
get name lqs # 获取数据
四. redis的常用命令
1. String的操作
set key value将单个字符串值value关联到key,存储到Redis1
2set name zs # key为 name, 值为zs
set age 21get key返回key关联的字符串值1
get name # 获取值,key为 name
mset key value key value同时设置一个或多个 key-value 对1
mset email [email protected] phone 10086 # 设置了两对key ,[email protected]; phone=10086
mget key key获取多个值1
mget name email # 获取key为name和email的数据的值
incr key将 key 中储存的数字值增1(key不存在,则初始化为0,再加1)1
incr age # age的值增加1
decr key将 key 中储存的数字值减1(key不存在,则初始化为0,再减1)1
decr age # 将age的值减去1
incrby key number将 key 中储存的数字值增加指定数字number1
incrby age 2 # 在age的值的基础上增加2
decrby by number将 key 中储存的数字值减少指定数字number1
decrby age 2 # 在age的值的基础上减去2
setex key seconds value设置key-value,并设置过期时间seconds (单位是秒)1
setex mykey 10 "Hello" # 设置 mykey的值为“hello” ,过期时间为 10s ,是set和expire的组合命令,且是原子性的
setnx key value设置一个key-value,如果这个key不存在则设置成功返回1,否则设置不成功,返回01
setnx name zs
setget key value设置一个key-value,把这个key以前的值返回1
getset name coderyeah
2. key的操作
keys *查看所有key1
keys *
del key删除指定的某个key1
del email # 删除key为email的数据
expire key seconds设置key的过期时间(secnods秒后过期)1
expire name 10 # 设置name的过期时间10s
ttl key查看key的过期时间1
ttl name # 查看name的过期时间
flushall清空整个redis服务器数据,所有的数据库全部清空1
flushall
flushdb清除当前库1
flushdb
select index选择数据库,redis中默认有16个数据库,名称分别为0,1,2,,,15 , index数据库索引1
select 1 # 选择第2个数据库
exists key查询key是否存在存在返回1,不存在返回01
exists name
3. List的操作
list集合可以看成是一个左右排列的队列(列表)
| key | value | value | value |
|---|---|---|---|
| names | zs | ls | ls |
| ages | 11 | 18 | 20 |
lpush key value1 value2...将一个或多个值 value 插入到列表 key 的表头(最左边)1
lpush names zs ls # 往key为 names 的list左边添加值“zs”和“ls”
lrange key names start stop返回列表 key 中指定区间内的元素,查询所有的stop为-1即可1
lrange names 0 -1 # 查看names的所有元素
rpush key value1 value2...将一个或多个值 value 插入到列表 key 的表尾(最右边)1
rpush names zl cq #往key为 names 的list右边添加值“zl”和“cq”
lpop key移除并返回列表 key 的头(最左边)元素1
lpop names # 移除并返回names列表的头(最左边)元素
rpop key移除并返回列表 key 的尾(最右边)元素。1
rpop names # 移除并返回names列表的尾(最右边)元素。
lrem key count value根据count值移除列表key中与参数 value 相等的元素count 0 : 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count 。count < 0 : 从表尾开始向表头搜索,移除与 value 相等的元素,数量为 count 的绝对值。count = 0 : 移除表中所有与 value 相等的值。1
2
3lrem names 1 zs # 删除names列表中左边第1个“zs”
lrem names 0 ls # 删除names列表中所有的“ls”
lrem names -1 cq # 删除names列表中右边第1个“cq”lindex key index返回列表 key 中,下标为 index 的元素1
lindex names 2 # 取names列表中索引为 2 的元素
ltrim key start stop对一个列表进行修剪 ,保留范围内的,范围外的删除1
ltrim names 2 4 # 删除names列表中索引为 2 - 4 以外的元素
dbsize或info keyspace查询当前数据库key数量1
2dbsize
info keyspaceRedis中如何实现栈和队列
- list控制同一边进,同一边出就是栈
- list控制一边进,另一边出就是队列
4. Set的操作
set集合是一个无序的不含重复值的队列
| key | value | value | value |
|---|---|---|---|
| idcards | 110 | 120 | 130 |
| phones | 182 | 135 | 136 |
sadd key value1 value2...将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略1
sadd colors red green yellow blue # 往colors这个set集合中存放元素: red,green,yellow,blue
smembers key返回集合 key 中的所有成员。1
smembers colors
srem key member移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略1
srem colors red # 删除colors中的 red元素
scard key返回集合存储的key的基数 (集合元素的数量).如果key不存在,则返回1
scard colors
sdiff key key返回一个集合与给定集合的差集的元素1
sdiff colors names
sismember key member返回成员 member 是否是存储的集合 key的成员.
如果member元素是集合key的成员,则返回1
如果member元素不是key的成员,或者集合key不存在,则返回0
1
sismember names zs # 判断names中是否包含 zs
五. Zset的操作
ZSet(sorted sets)在Set基础上增加了“分数”,让set集合有了排序功能
| key | value(score) | value(score) | value(score) |
|---|---|---|---|
| names | zs(10) | ls(20) | ww(30) |
zadd key score value score value将所有指定成员添加到键为key有序集合(sorted set)里面,如果指定添加的成员已经是有序集合里面的成员,则会更新改成员的分数(scrore)并更新到正确的排序位置1
zadd heights 150 zs 160 ls #有序集合heights中zs的分数为150 ,ls的分数是 160
zcard key返回key的有序集元素个数。key存在的时候,返回有序集的元素个数,否则返回0。1
zcard heights
zcount key min max返回有序集key中,score值在min和max之间(默认包括score值等于min或max)的成员。1
zcount heights 150 160 # 获取heignhts中分数为 150到160的元素数量
zpopmax key count删除并返回有序集合key中的最多count个具有最高得分的成员。如未指定,count的默认值为1。1
zpopmax heights 2 # 删除最高分数的前2个元素
zpopmin key count删除并返回有序集合key中的最多count个具有最低得分的成员。如未指定,count的默认值为11
zpopmin heights 2 # 删除最低分数的前2个元素
zrange key start stop WITHSCORES返回存储在有序集合key中的指定范围的元素。 返回的元素可以认为是按得分从最低到最高排列。 如果得分相同,将按字典排序。返回给定范围内的元素列表(如果指定了WITHSCORES选项,将同时返回它们的得分)1
zrange heights 0 10 WITHSCORES # 返回heights中索引 0 到 10 的元素和其分数
zrank key member返回有序集key中成员member的排名。其中有序集成员按score值递增(从小到大)顺序排列。排名以0为底,也就是说,score值最小的成员排名为01
zrank heights zs # 返回 zs在heights的分数从小到大排名
zreverank返回有序集key中成员member的排名,其中有序集成员按score值从大到小排列。排名以0为底,也就是说,score值最大的成员排名为01
zreverank heights zs # 返回 zs在heights的分数从大到小排名
zscore返回有序集key中,成员member的score值。如果member元素不是有序集key的成员,或key不存在,返回nil。1
zscore heights zs #返回 zs的分数
ZREVRANGE key start stop [WITHSCORES]返回有序集key中,指定区间内的成员。其中成员的位置按score值递减(从大到小)来排列。具有相同score值的成员按字典序的反序排列1
ZREVRANGE heights 1 2 WITHSCORES #返回索引1 - 2 的成员,按分数大到小排序
ZRANGEBYSCORE key min max WITHSCORES LIMIT offset count返回有序集合中指定分数区间内的成员,分数由低到高排序,LIMIT控制分页1
ZRANGEBYSCOREkey heights 0 170 WITHSCORES LIMIT 0 10 #查询heights中0-170分之间的元素,低到高排序,0条 #开始查询,每页10条
5. Hash的操作
Hash类似于jdk中的Map,一个key下面以键值对的方式存储数据
HSET key field value设置 key 指定的哈希集中指定字段的值。如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联。如果字段在哈希集中存在,它将被重写。1
hset user:1 name zs # 给"user:1"这个key设置name=zs键值对
hget key field获取hash类型的name键对应的值1
hget user:1 name #获取user:1总的name字段
批量添加name=value键值对到key这个hash类型
1
hmset user:2 name zs age 18 #给"user:2"这个key设置name=zs键值对和age=18键值对
批量获取hash类型的键对应的值
1
hmget user:2 name age # 获取user:2总的name和age字段
返回哈希表 key 中的所有键
1
hkeys user:2 #返回user:2总的所有字段
返回哈希表 key 中的所有值
1
hvals user:2 #返回user:2中的所有值
返回哈希表 key 中,所有的键和值
1
hgetall user:2 #返回user:2中所有key和value
5.1 存储对象的两种方式
使用string结构
1
set user:1 {id:1,name:zs}
使用Hash
1
hset user:2 {id:2,name:ls}
5.2 sort key
对 list ,set ,zset进行排序
1 | SORT ages #对年龄集合进行排序 |
五. Redis设置密码
CONFIG SET 命令可以动态地调整 Redis 服务器的配置而无须重启,重启后失效
1
CONFIG SET requirepass 123456 #临时生效
修改配置文件
redis.widows.conf,增加代码:1
requirepass 123456 #永久修改
Auth认证:启动redis-cli.exe ,执行auth命令:
1
auth 123456
六. Java集成jedis
开始在 Java 中使用 Redis 前, 我们需要确保已经安装并启动 redis 服务及 Java redis 驱动,且你的机器上能正常使用 Java。可以取Maven仓库下载驱动包 下载 jedis.jar
导入依赖
1
2commons-pool2-2.2.jar #连接池
jedis-2.5.2.jar #Jedis核心包通过Jedis客户端对象连接Redis,调用API进行Redis
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public void testJedis()throws Exception{
//创建连接
String host ="127.0.0.1";
//端口
int port = 6379;
//超时时间,1秒超时
int timeout = 1000;
//jedis客户端
Jedis jedis = new Jedis(host,port,timeout);
//认证
jedis.auth("123456");
//执行操作,保存值
jedis.set("username","wang da cui");
//获取值
String result = jedis.get("username");
System.out.print(result);
//关闭连接
jedis.close();
}连接池:如果直接使用
Jedis连接Redis会造成频繁的Jedis对象创建和销毁,对性能会有很大的影响,所以我们会选择使用连接池来链接性能。原理同Mysql连接池1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public void test()throws Exception{
//1 创建jedispool配置对象
JedisPoolConfig config = new JedisPoolConfig();
//2 做配置
//最大空闲连接数
config.setMaxIdle(2);
//最大链接对象数
config.setMaxTotal(10);
//链接超时时间
config.setMaxWaitMillis(1*1000);
//获取连接是测试连接是否畅通
config.setTestOnBorrow(true);
//3 创建jedispool连接池对戏
//参数:配置对象,redis主机地址 ,超时时间,密码
JedisPool pool = new JedisPool(config,"127.0.0.1",6379,1*1000,"123456");
//4 通过jedispool获取连接
Jedis jedis = pool.getResource();
//5 执行操作
jedis.set("age",10);
String result = jedis.get("age");
System.out.println(result);
// 6 释放连接 , 底层做了兼容,如果是连接池操作就是释放,如果是连接操作就是关闭
jedis.close();
// 7 摧毁连接池-如果是真正项目中它应该是一个受spring管理的单例
pool.destroy();
}
七. 发布订阅
什么是发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis 客户端可以订阅任意数量的频道。没订阅的接受者当然是接受不到消息的,(pub/sub)是一种广播模式,及会把消息发送给所有的订阅者。
1
SUBSCRIBE cctv #cctv作为订阅的频道,可以任意定义名字
1
PUBLISH cctv '我是消息,发往cctv频道,over'
八. SpringBoot集成Redis
依赖
1
2
3
4
5<!--spirngboot springdata对redis支持-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>配置
1
2
3
4
5
6
7
8
9
10
11
12#数据源配置
spring:
redis:
database: 0
host: 127.0.0.1
port: 6379
password: 123456
jedis:
pool:
max-wait: 2000ms
min-idle: 2
max-idle: 8测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class SpringbootDataRedisApplicationTests {
private RedisTemplate redisTemplate;
public void test() throws Exception{
redisTemplate.opsForValue().set("name","zs");
System.out.println(redisTemplate.opsForValue().get("name"));
}
}
九. Redis的持久化配置
什么是Redis持久化
因为Redis数据基于内存读写,为了防止Redis服务器关闭或者宕机造成数据丢失,我们通常需要对Redis做持久化化,即:把内从中的数据(命令)保存一份到磁盘做一个备份,当Redis服务关闭或者宕机,在Redis服务器重启的时候会从磁盘重新加载备份的数据,不至于数据丢失。 Redis 提供了两种不同级别的持久化方式:RDB和AOF,可以通过修改redis.conf来进行配置。
开启持久配置后,对Redis进行写操作,在Redis安装目录将会看到持久文件:“appendonly.aof”和“ dump.rdb”。
Redis如何保存数据
redis为了考虑效率,保存数据在内容中.并且考虑数据安全性,还做数据持久化,如果满足保存策略,就会把内存的数据保存到数据rdb文件,还来不及保存那部分数据存放到aof更新日志中。在加载时,把两个数据做一个并集。
Redis持久化-RDB
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照,默认开启该模式
如何关闭 rdb 模式?修改配置文件注释如下内容
1
2
3
4save "" # 关闭RDB
save 900 1 #至少在900秒的时间段内至少有一次改变存储同步一次
save 300 10
save 60 10000
Redis持久化-AOF
AOF 持久化记录服务器执行的所有
写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集,默认关闭该模式。如何开启aof模式?修改配置文件如下内容
1
2
3
4
5
6
7
8appendonly yes #yes 开启,no 关闭
appendfsync always #每次有新命令时就执行一次fsync
appendfsync everysec #每秒 fsync 一次 ,这里我们启用 everysec
appendfsync no #从不fsync(交给操作系统来处理,可能很久才执行一次fsync)
#其它的参数请大家看redis.conf配置文件详解
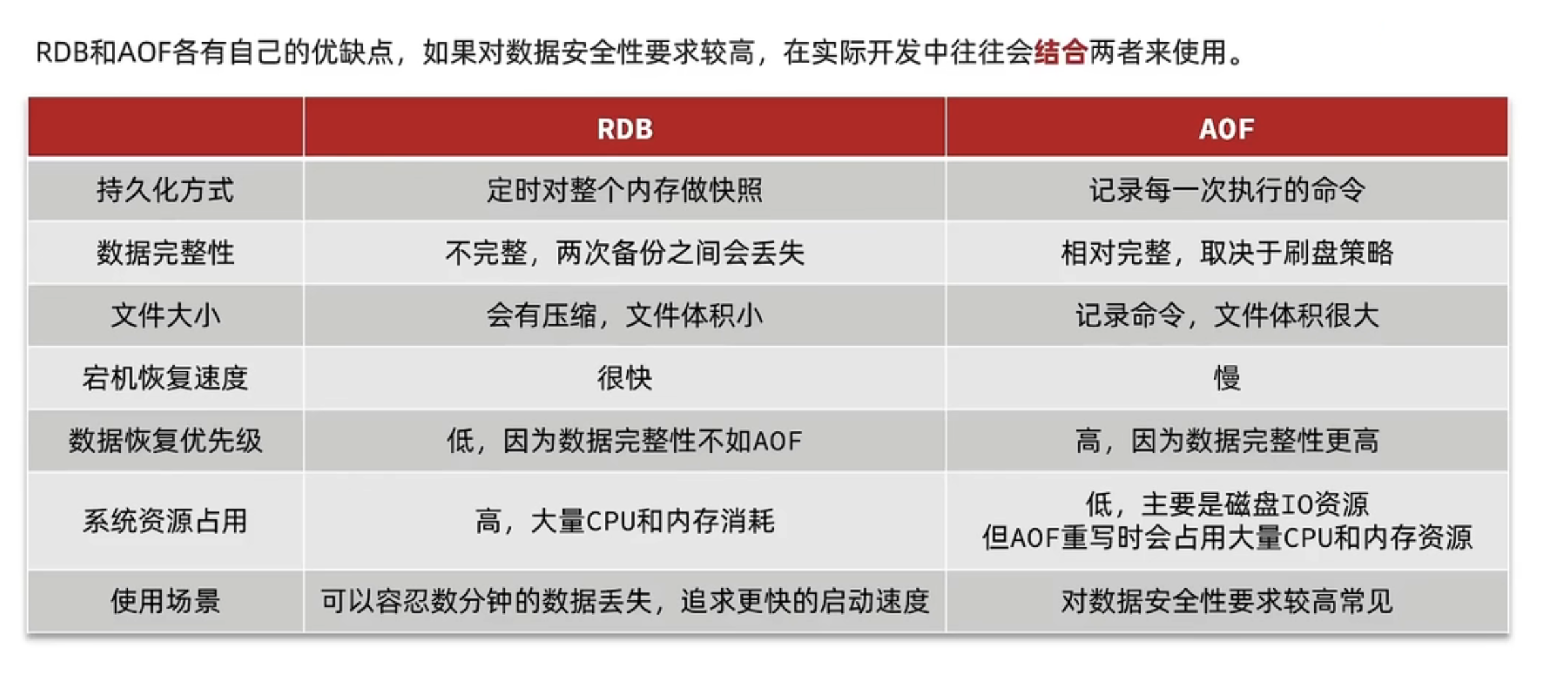
RDB和AOF区别
RDB
RDB持久化是指在
指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24RDB:记录数据快照
优点:
1.产生一个持久化文件,方便文件备份 , 灾难恢复RDB是非常不错的选择
2.Fork子进程去持久化, 性能比AOF好,文件体积更小,启动时恢复速度快
缺点:
1.没办法100%s数据不丢失
2.数据集大,FORk子进程持久化时会服务器卡顿
AOF: 记录写命令
优点:
1.数据更安全
2.采用Append,即使持久的时候宕机,也不影响已经持久的数据
3.日志过大,可以rewrite重写
4.AOF日志格式清晰,容易理解
缺点:
1.AOF文件通常要大于RDB文件
2.AOF数据恢复比RDB慢
最佳实践:二者结合 ,RDB来数据备份,迁移,容灾 。 AOF持久化保证数据不丢失。
十. Redis的淘汰策略
为什么要淘汰
Redis的数据读写基于内存,Redis虽然快,但是内存成本还是比较高的,而且基于内存Redis不适合存储太大量的数据。Redis可以使用电脑物理最大内存,当然我们通常会通过设置
maxmemory参数现在Redis内存的使用, 为了让有限的内存空间存储更多的有效数据,我们可以设置淘汰策略,让Redis自动淘汰那些老旧的,或者不怎么被使用的数据。redis 确定驱逐某个键值对后,会删除这个数据并将这个数据变更消息发布到本地(AOF 持久化)和从机(主从连接)。
策略
1.noeviction
不进行数据淘汰,也是Redis的默认配置。这时,当缓存被写满时,再有写请求进来,Redis不再提供服务,直接返回错误。
2.volatile-random
缓存满了之后,在设置了过期时间的键值对中进行随机删除。
3.volatile-ttl
缓存满了之后,会针对设置了过期时间的键值对中,根据过期时间的先后顺序进行删除,越早过期的越先被删除。
4.volatile-lru
缓存满了之后,针对设置了过期时间的键值对,采用LRU算法进行淘汰。
5.volatile-lfu
缓存满了之后,针对设置了过期时间的键值对,采用LFU的算法进行淘汰。
6.allkeys-random
缓存满了之后,从所有键值对中随机选择并删除数据。
7.allkeys-lru
缓存满之后,使用LRU算法在所有的数据中进行筛选删除。
8.allkeys-lfu
缓存满了之后,使用LFU算法在所有的数据中进行筛选删除。

十. 面试题======https://blog.csdn.net/wchengsheng/article/details/79925654
Redis有哪些数据结构
1、String字符串类型;2、hash哈希;3、链表;4、set集合;5、zset有序集合。其中,String字符串是一种动态字符串,是Redis中最基础的数据存储类型,它在Redis中是二进制安全的,这便意味着该类型可以接受任何格式的数据,使用者可以进行修改。
如果你是Redis中高级用户,还需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub,BitMap.使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要抓一抓自己得脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis是单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。